출처 : http://blog.daum.net/miracle_jhw/14
1장. Pro*C 소개와 기본 특징
1-1. Pro*C 개요
SQL 문은 절차형 언어가 아니다. 그래서 오라클을 포함한 많은 데이터베이스는 PL/SQL이라는 절차형 언어를 제공한다.
DBMS의 버전이 높아지면서 이전과 다르게 PL/SQL에도 다양한 기능이 추가되었다. 예를 들면, TCP/IP, HTTP, FILE I/O 등과 같은 기능이 추가되어 다양한 방식의 프로그래밍이 가능해졌다. 하지만 오라클 외부 프로그램과의 연동 등에 있어서 많은 제약이 있는데, 이런 제약을 해결하기 위해서 대부분의 DBMS 벤더는 외부 C 프로그램과 결합할 수 있는 선행 컴파일러를 제공하고 있으며 오라클에서는 이를 Pro*C라고 한다.
PL/SQL(Procedural Language/Structured Query Language)이란? : 오라클 DBMS에 의해 실행되는 트리거나 축적 절차 등을 작성하기 위해 사용되는 오라클의 프로그래밍 언어이다. 이것은 또한 SQL 질의에 의해 반환된 데이터에 대해, 정렬 등의 처리를 하기 위해 사용되기도 한다. PL/SQL 프로그램은 선언부, 실행명령어들, 그리고 예외처리 부분 등으로 구성되는, 하나의 블록으로 구조화되어 있다.
DBMS(DataBase Management System)란? : 다수의 컴퓨터 사용자들이 데이터베이스 안에 데이터를 기록하거나 접근할 수 있또록 해주는 프로그램이다.
TCP/IP(Transmission Control Protocol/Internet Prorocol)란? : 인터넷의 기본적인 통신 프로토콜로서, 인트라넷이나 엑스트라넷과 같은 사설 망에서도 사용된다. 사용자가 인터넷에 접속하기 위해 자신의 컴퓨터를 설정할 때 TCP/IP 프로그램이 설치되며, 이를 통하여 역시 같은 TCP/IP 프로토콜을 쓰고 있는 다른 컴퓨터 사용자와 메시지를 주고받거나, 또는 정보를 얻을 수 있게 된다.
HTTP(HyperText Transfer Protocol)란? : 초본문전송규약,하이퍼본문전송규약으로 WWW(World Wide Web)상에서 정보를 주고 받을 수 있는 프로토콜이다. 주로 HTML(HyperText Markup Language) 문서를 주고 받는 데에 쓰인다.
1-2. Proc* 확장 범위
Pro*C는 오라클 데이터베이스와 연동할 수 있는 C 프로그램이다. C프로그램이기 때문에 C프로그램으로 처리할 수 있는 다양한 기능을 Pro*C로도 처리할 수 있다. Pro*C의 확장범위를 요약하면 다음과 같다.
1. 야간 혹은 주간 배치 프로그램
2. 미들웨어 프로그램(Tuxedo, Tmax, Entera)
3. OLTP 프로그램
- TCP/IP 모듈과 결합한 자료 생성 및 전송 프로그램(EDI)
- 온라인 프로그램으로 이루어진 다량의 자료 가공 프로그램을 Pro*C로 이관하여 성능 개선
Tuxedo 란? : Oracle Tuxedo는 지난 30년 간 수 많은 배치를 통해 성능면에서 신뢰를 얻은 전세계적으로 가장 많이 사용되는 컴퓨팅 플랫폼 중 하나이다. 이플랫폼은 최신 SOA(서비스 중심 아키텍처)표준 및 기술과 수년에 걸쳐 입증된 오라클의 신뢰성, 성능 및 성숙도가 결합되어 미션 크리티컬 애플리케이션이 사용자의 환경에 가장 적합하게 사용될수 있도록 지원한다.
Tmax(Transaction MAXimization) 란? : 분산된 환경에서 다른 기종 컴퓨터 간의 트랙잭션 처리와 부하분산 동작을 처리하고 오류가 발생할 때 그에 알맞은 조치를 담당하는 티맥스소프트의 TP모니터(TP-Monitor)제품이다.
OLTP(On-Line Transaction Processing) 란? : 온라인 업무의 처리 형태의 하나이다. 터미널에서 받은 메시지를 따라 호스트가 처리를 하고, 그 결과를 다시 터미널에 되돌려주는 방법을 말한다.
1-3. 프로그램 작성 방식
4GL 프로그램으로 DB 핸들링 프로그램을 작성하기 위해서는 DB접속 방식을 선택해야 한다.
ex) ODBC 방식, OLE-DB 방식 (현재 업무에서 ODBC방식을 사용하고 있다.. 왠지 익숙한 느낌이다..)
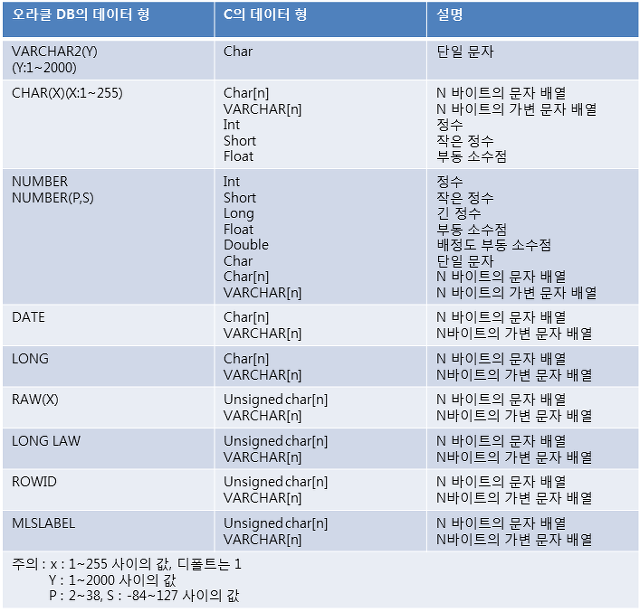
Pro*C 는 코딩 시점에서 Header 파일 선정, 프로그램 방식의 선정, 컴파일 옵션의 변경을 통해 작성 방식을 선택하여 사용할 수 있다. Pro*C 에서 프로그램 작성 방식은 두 가지로 나뉘며, 하나는 내장 SQL 방식이고, 다른 하나는 OCI(Oracle Call Interface) 방식이다.
ODBC(Open DataBase connectivity) 란? : 어떤 응용프로그램을 사용하는지에 관계없이, 데이터베이스를 자유롭게 사용하기 위하여 만든 응용프로그램의 표준방법을 말한다.
OLE-DB(Object
Linking and Embedding, Database) 란? : 마이크로소프트사가 개발한 API로, 통일된 방식으로 저장된
여러 종류의 데이터에 접근하기 위해서 만들어졌다. 컴포넌트 오브젝트 모델(COM)을 사용하여 추가된 인터페이스 집합이며 객체 연결
삽입과는 관련이 없다. ODBC를 높은 수준으로 대체하면서도 그 뒤를 잇도록 설계되었다.
(1) 내장 SQL 방식
내장 SQL 방식이란 C 프로그램 내부에서 'EXEC SQL' 이라는 접두사 뒤에 SQL 문장을 직접 기술하는 방식이다.
내장 SQL 문장에는 일반 SQL 문장뿐만 아니라 오라클을 이용한 다양한 형식의 내부 문장을 사용할 수 있으며, 미리 생성되어 있는 Stored Procedure, Package 또는 개발자가 임의로 작성한 PL/SQL도 사용할 수 있다. 즉, 오라클 데이터베이스에서 사용하는 모든문장 DML, DDL, DCL, PL/SQL, 일반 SQL 문장을 내장 SQL 문장에 사용할 수 있다.
※ 내장 SQL 문장 구문 방식의 프로그램 구문
(2) OCI 방식
OCI(Oracle Call Interface) 방식이란 OCI 라이브러리를 통해서 오라클 SQL 문장을 직접 호출하여 사용하는 방식이다.
장
점: 내장 SQL 방식에 비해서 조금 더 하위 레벨에 해당하는 프로그래밍 방식으로서 OCI를 통해서 DB핸들링 작업을 실행하기
때문에 데이터베이스 서버의 자원을 효율적으로 관리하고 SQL 문장 수행의 각 단계를 직접 제어할 수 있다
단점: 프로그래밍 방법에 있어 내장 SQL 프로그램에 비해 복잡하기 때문에 개발자의 숙련도가 요구된다는 단점이 있다.
이 책은 내장 SQL 문장 방식을 사용하고, OCI 방식 프로그램에 대해서는 다루지 않는다.
※ 내장 SQL 방식과 OCI 방식 비교
1-4. Pro*C의 데이터 형
Pro*C에서 사용하는 데이터 형은 C 프로그램에서 사용하는 일반적인 데이터 형과 Pro*C에서만 사용할 수 있는 고유한 형태의 데이터 형으로 구성되어 있다.
Pro*C 프로그램에서 사용하는 데이터형
- 기본적인 데이터 형의 일차원 배열
- CHAR 데이터 형과 VARCHAR 데이터 형의 이차원 배열
- 기본적인 데이터 형에 대한 포인터
- 사용자 정의의 typedef
- 구조체
- 배열의 구조체
- 구조체에 대한 포인터
- 구조체 배열
Pro*C 역시 C 프로그램이기 때문에 C의 일반적인 데이터 형을 사용할 수 있다. 오라클 데이터베이스의 데이터 형과 C 프로그램의 데이터 형은 호환 된다.
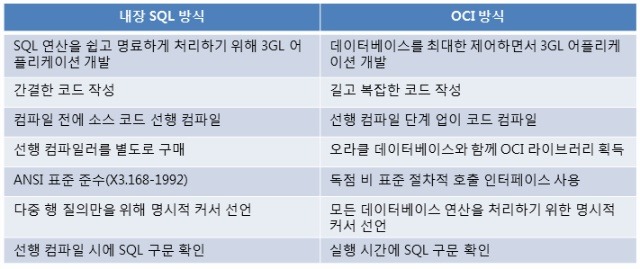
※ 오라클 데이터 형과 C 데이터 형의 호환성
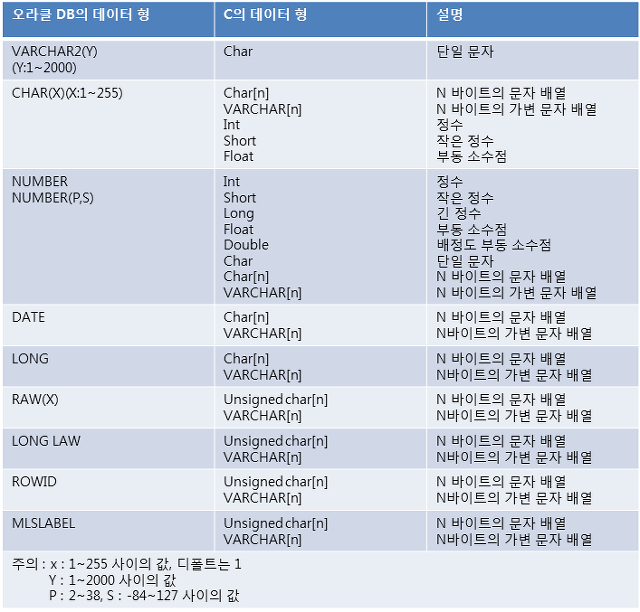
오라클의 데이터형과 C의 데이터 형은 위 표와 같이 치환하여 사용할 수 있다. 그러므로 오라클 데이터베이스와 연결해서 프로그래밍을 함에 있어 큰 제약이 없다.
다만 VARCHAR 형의 경우 데이터 형의 특성상 VARCHAR uid[20]으로 선언하면 실제로는 구조체 형식으로 다음과 같이 생성된다.
struct{
unsigned short int len;
unsigned char arr[20];
}uid;
사용법 또한 구조체이기 때문에 C의 char 타입과 다르게 구조체의 사용법을 따른다.
VARCHAR uid[20];
strcpy((char*)uid.arr, "userid");
uid.len = (short)strlen((char*)uid.arr);
char
형은 Fixed Data Type 으로 데이터 형의 길이만큼 저장 공간을 차지하고, VARCHAR 형은 데이터의 길이와 상관없이
할당받은 데이터 길이만큼의 저장 공간을 갖는다. 또한, VARCHAR형은 구조체 및 포인터로의 형변환이 필요하므로 사용의 편이성은
떨어진다.
Pro*C 프로그램에서 저장 공간과 처리 방법에 있어서 차이를 보이는 데이터 형은 char형과 VARHCAR 형 밖에 없다.
2장. Pro*C 오류 진단과 처리
프 로그램을 작성할 때 가장 중요한 것은 오류에 대한 정확한 핸들링과 그에 대한 처리이다. 프로그램 오작동 시 원인이 무엇인지와 오작동의 원인을 해결하기 위해 무엇이 필요한지를 정확히 짚어낼 수 있어야 한다. 에러나 경고를 감지하고 에러에 대해 더 많은 정보를 얻기 위해서는 별도 통신 영역의 정보를 가진 도구가 필요하며 Pro*C에서는 SQL 통신 영역(SQLCA)과 오라클 통신 영역(ORACA)이라는 두 개의 특수한 데이터 구조를 지원한다.
2-1. SQLCA (SQL Communication Area : SQL 통신 영역)
모든 Pro*C 프로그램에서 프로그램 실행에 관한 정보를 데이터베이스와 교환하기 위해서 SQLCA를 필수로 사용한다. C 프로그램에서 헤더 파일을 사용할 때와 같이 프로그램의 시작 부분에 헤더 파일을 첨부해서 사용할 수 있다.
SQLCA 는 예외와 경고를 감지한다. SQL 문 속에 변수의 수가 너무 적어서 요구된 데이터를 반환할 수 없는 경우나, 데이터 추출 시 추출하려는 데이터가 없는 경우(ORA-1403) 등 다양한 경우의 에러와 경고에 대해 SQLCA는 SQL 문장의 실행 시점에서 이를 감지하고 출력한다.
사용법 : #include <sqlca.h> - C 프로그램 방식
EXEC SQL INCLUDE SQLCA; - Pro*C 문법
SQLCA는 직전의 SQL 문장의 처리 결과에 대해 SQLCA 파일에 정의되어 있는 sqlca 구조체에 정보를 저장한다.
그러므로 개발자는 각 SQL 문장마다 SQLCA의 구조체 내용을 검색하여 에러와 경고 여부에 대한 정보를 확인할 수 있다.
SQLCA는 다음과 같은 정보를 가지고 있다.
- 경고 플래그와 처리 상황에 관한 정보
- 에러 코드
- 진단 정보
SQLCA 구조체의 개괄적인 구조 및 구조체의 각 멤버 상세 내용은 본책 18 ~ 20 page 를 참고.
실제 프로그램에서 SQLCA를 사용하는 예제는 20 page 참고.
2-2. ORACA
ORACA 는 SQLCA에서 얻을 수 있는 것 보다 조금 더 많은 정보를 얻을 수 있는 데이터 구조이다. ORACA는 실행 시 발생하는 에러뿐만이 아니라, 성능 통계에 대한 보조 정보도 제공한다. ORACA는 필수가 아닌 선택이며 SQLCA와 동일하게 Include 부분에서 참조하여 사용한다.
ORACA는 다음과 같은 정보를 가지고 있다.
- 현재 SQL 문의 텍스트(orastxt)
- 에러가 있는 파일의 이름(orasfrm)
- 에러가 있는 행의 번호(oraslnr)
- SQL 문 보존 플래그(orastxtf) : 이 플래그를 설정함으로써 어느 조건으로 문을 보존할 것인지를 선택할 수 있다.
- DEBUG 처리의 사용 허가 플래그: 이 플래그는 0이나 1을 설정할 수 있으며, 1을 설정한 경우에는 모든 DEBUG 처리를 사용할 수 있다.
- 커서 캐시 검사(orahchf)
ORACA 구조체의 구조 및 구조체의 각 멤버 상세 내용은 23 ~ 24 page 참고.
실제 프로그램에서 ORACA를 사용하는 예제는 25~26 page 참고.
2-3. 오류 검출 및 처리
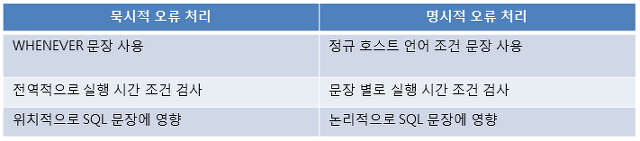
오류 검출과 처리 방법에는 명시적 오류 처리 방식과 묵시적 오류 처리 방식 2가지가 있다.
(1) 명시적 오류 처리
Pro* C 프로그램 안의 SQL 문장 또는 EXEC SQL 문장을 실행한 후에 매번 SQL 문장의 오류를 검사하고 이에 대한 처리를 기술하는 방식이다. 즉, 발생하는 가능한 모든 부분을 명시적으로 기술하여 처리하는 방법으로서 가장 많이 사용된다.
장점 : 개발자가 직접 SQL 문장 밑에 기술하게 되므로 원하는 처리 방식이 가능하다.
단점 : 미처 기술하지 못한 부분에 대한 오류 검출이 불가능하며, 개발자의 실수에 무방비로 노출된다.
(2) 묵시적 오류 처리
모든 SQL 문장과 EXEC SQL 문장 실행 후에 오류 처리를 기술하는 것이 아니라, 전역적 혹은 지역적으로 오류가 발생했을 때의 처리 방안을 기술하여 모든 오류에 동일한 처리 방식을 적용한다.
장점 : 모든 오류 또는 경고에 대해 동일한 처리가 가능하며, 개발자의 실수에 의한 누락이 발생하지 않는다.
단점 : 본 책에 서술 되어 있지 않다.
일반적으로 간단한 프로그램에서는 명시적 처리를, 코드라인이 많은 프로그램이거나 팀 코딩을 하는 경우에는 묵시적 처리를 선호하는 편이다.
※ 명시적 오류 처리와 묵시적 오류 처리 비교
묵시적/명시적 오류 처리의 실제 사용 예제는 28~ 34 page 참조.
!! 개발의 필수 덕목이 오류 처리라는 것을 꼭 명심하자.